
Introdução
Desde a crise de software na década de 1970 (veja aqui), foram desenvolvidas metodologias de desenvolvimento, como SCRUM e Kanban, que servem para gerenciar melhor a equipe e assim evitar atrasos, sobrecarga de função e prazos curtos.
Além dessas metodologias, surgiram também convenções nos módulos de um projeto de software. Por exemplo, as regras para a criação de tabelas de banco de dados e gerenciamento destes arquivos (como CRUD,); Formas de esquematizar as páginas de um site web ou as telas de um aplicativo (MVC); Em questão de código, há também uma vasta literatura sobre como escrevê-los de forma clara e como documentá-los (PEP-8 para o Python, por exemplo).
Essas e outras melhorias, se implementadas, convergem para um software preparado para durar muitos anos depois de desenvolvido, pois elas previnem a perda total de um módulo simplesmente pela ausência de explicação de sua função dentro do código como um todo. Consequentemente, previnem também uma situação muito temida por todos os integrantes do projeto: o retrabalho.
Na área de ciência de dados, esses problemas também aparecem. Um notebook escrito na plataforma Jupyter por uma equipe de ciência de dados, se mal explicado ou negligenciada a documentação do mesmo, pode levar modelos, gráficos e até mesmo um dataset inteiro a ser descartado.
Portanto, neste texto serão descritas algumas dicas simples sobre o que não deixar de colocar em um notebook para garantir sua legibilidade e aplicabilidade, que chamaremos de Notebook Limpo - derivado do conceito de Clean Code de Robert C. Martin (Tio Bob).
Criando um notebook limpo
Nomenclatura e localização do documento
Vamos primeiro descrever um cenário: recebemos uma tarefa dos nossos superiores para que encontrássemos o melhor modelo para os dados referentes ao dataset do Titanic. Sim, sabemos que você já decorou as análises deste dataset, mas que tal ver ele bem documentado?
Então vamos abrir um notebook:
Dica: procure o local certo da pasta que você vai colocar este notebook, porque se não, irá se aventurar nos diretório do seu computador toda vez que abrir este notebook, ou seja:

Agora execute este comando. Surgirá um link no terminal que dá acesso a esta pasta no navegador. Crie um notebook com um nome bem intuitivo, pois é provável que este não seja o único que você fará. Não deixe notebooks importantes nomeados como Untitled.ipynb! Nomeie-o de forma clara para que quem acessá-lo saiba o que será encontrado nele. Um bom nome seria, por exemplo: procurando_o_modelo_para_o_dataset_titanic.ipynb. Feito isso, teremos:
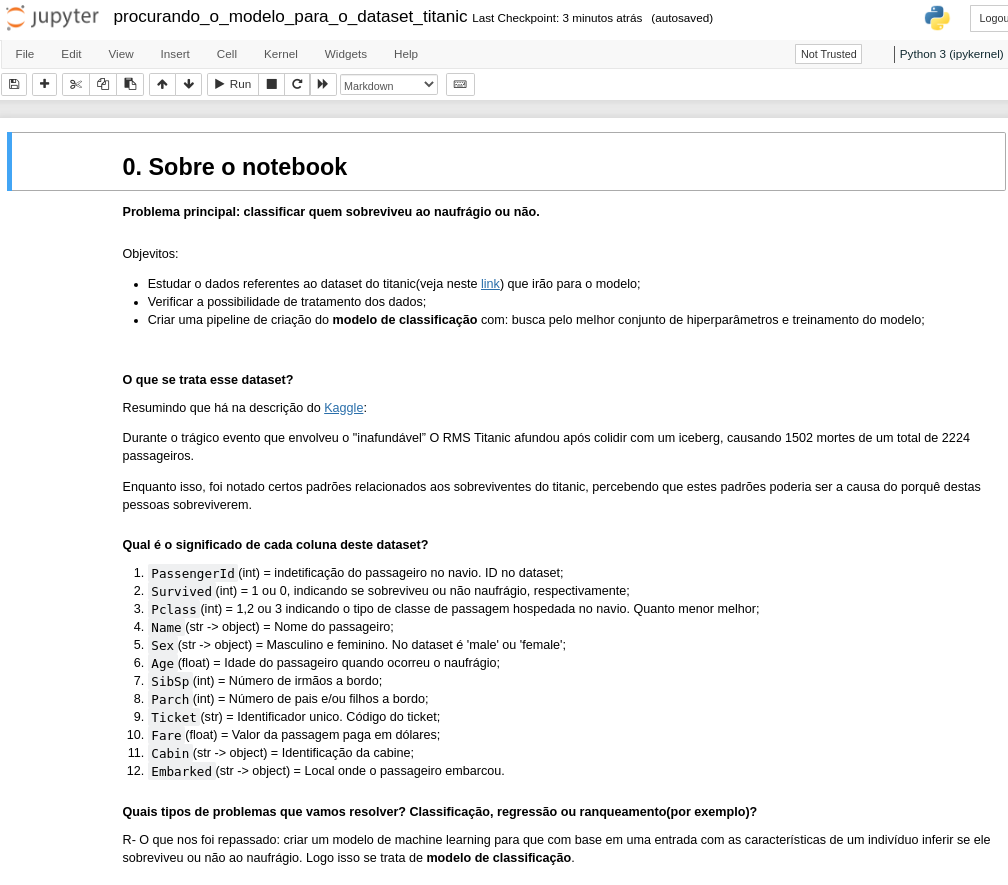
Contextualização
Criado nosso notebook, o próximo passo é descrever os nossos objetivos nele, ou melhor, responder perguntas importantes com base na tarefa que foi passada:
- Do que se trata o dataset que será utilizado?
- Qual é o significado de cada coluna deste dataset?
- Quais tipos de problemas que tentaremos resolver? Classificação, regressão ou ranqueamento, etc ?
- Quais modelos vamos testar?
- Como serão testados?
- Quais métricas usaremos para escolher o melhor modelo?
Sem nenhuma exploração dos dados, já surgiram seis perguntas! Quanto mais perguntas forem feitas, melhor será o entendimento do problema e mais preciso serão nossos insights sobre o modelo a ser criado e seus resultados. Com as perguntas organizadas, podemos respondê-las no início do notebook.
Mas como fazer isso? Notebooks são estruturados em células, podendo ser tratadas como código (seja em qualquer linguagem), texto em markdown, ou outras formas. Então, a dica ao iniciar o notebook é: comente o que será feito. No nosso exemplo, é respondendo as perguntas listadas acima:
Sendo assim, caso haja um novo integrante na equipe, ou se esse notebook for repassado para o cliente, todo o contexto do trabalho estará explicitado logo de início.
Configuração de ambiente
Feito isso, vamos ao código. Normalmente colocam-se os principais imports de bibliotecas e configurações na primeira célula de código, logo depois da descritiva do propósito do notebook, pois fica claro como o ambiente foi configurado. Por exemplo, nesta célula podemos colocar a semente dos valores aleatórios ou também desabilitar warnings (se eles forem realmente desnecessários).
Vale ressaltar que a medida que seu notebook se estende em conteúdo, é interessante dividi-lo em seções e/ou subseções. No nosso caso, já temos duas. Podemos nomeá-las como: “0. Sobre o notebook” e “1. Configurando o ambiente”.
Configuração de ambiente
Feito isso, vamos ao código. Normalmente colocam-se os principais imports de bibliotecas e configurações na primeira célula de código, logo depois da descritiva do propósito do notebook, pois fica claro como o ambiente foi configurado. Por exemplo, nesta célula podemos colocar a semente dos valores aleatórios ou também desabilitar warnings (se eles forem realmente desnecessários).
Vale ressaltar que a medida que seu notebook se estende em conteúdo, é interessante dividi-lo em seções e/ou subseções. No nosso caso, já temos duas. Podemos nomeá-las como: “0. Sobre o notebook” e “1. Configurando o ambiente”.
Modelagem e testes
Com o contexto definido, o dataset explicado e o ambiente configurado, agora é mão na massa! De acordo com nossos objetivos, testamos os seguintes algoritmos: Random Forest, Gaussian Naive Bayes e LDA. Visando a organização, é recomendado colocar cada um deles numa subseção dentro de “3. Testando os modelos”, nomeadas com os respectivos algoritmos empregados.


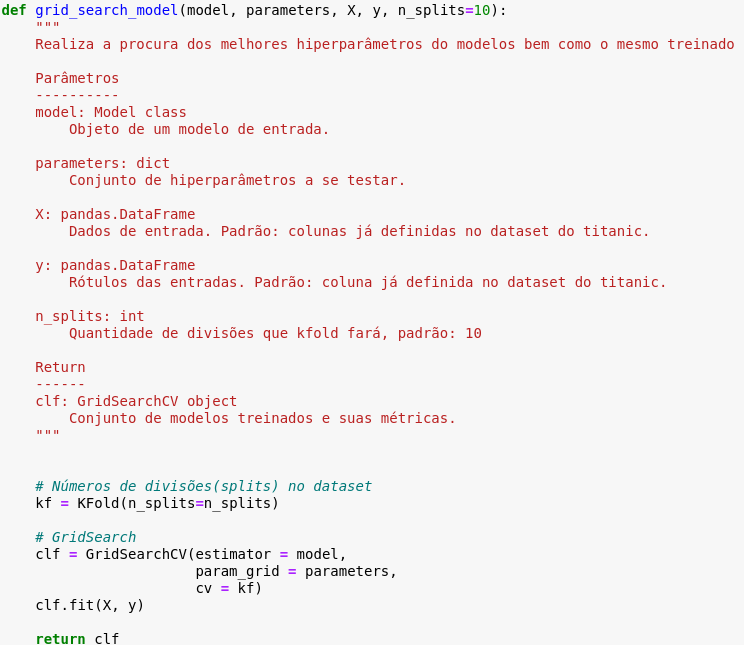
Além disso, quando houverem procedimentos que se repetem ao longo do notebook (como a divisão do dataset entre treino e teste ou o instanciamento dos modelos e seus hiperparâmetros), podemos colocá-los em funções bem comentadas de acordo com a PEP-8, como mostrado o exemplo abaixo:
Outro ponto muito importante: durante o processo de desenvolvimento é bastante provável que surgirão insights sobre os resultados, outros modelos e métricas. Não deixe de registrar suas descobertas, anote-as no notebook! Lembre-se que os leitores não estarão na sua mente para entender os pormenores de suas ideias ao desenvolver o documento!
Além disso, coloque todas as métricas que utilizou de forma padronizada. Assim você, sua equipe e/ou o cliente já saberá por onde começar a comparar. Por exemplo:
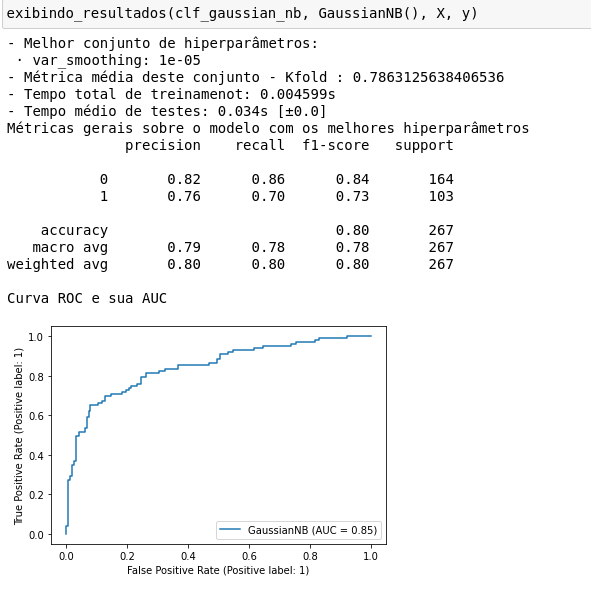
A padronização auxilia tanto na produção dos estudos quanto no seu entendimento. Dessa forma, todos os modelos que foram estudados possuem o mesmo formato de saída, não necessitando de uma outra tratativa de saídas para comprar os resultados mais facilmente.
Conclusões
Para finalizar a documentação, coloque uma sessão como “4. Considerações finais” ou “4. Conclusões”, trazendo os resultados finais do estudo - no nosso exemplo, qual foi o melhor modelo e o porquê dele ser o melhor. Busque a clareza e a objetividade!
Com isso, revise os seus feitos (como se estivesse finalizando uma prova ou uma redação) para não deixar nada passar. Por fim, mostre os resultados à sua equipe e seus superiores.

Conclusões sobre o que aprendemos
Vimos que documentar bem um notebook facilita a leitura do código que foi desenvolvido e as conclusões obtidas dele, tornando-o um material de referência para estudos e desenvolvimentos futuros ou um entregável de valor ao seu cliente!
Caso todo este texto não tenha lhe convencido da importância da documentação, faça um teste: pegue algum notebook que você comentou pouco ou nada e compare com outro que esteja bem escrito. Verá que o último servirá para você por muito tempo (na escala de anos!) por simplesmente descrever cada ideia e pensamento que você teve nele.