
Otimizar um modelo de machine learning é um dos temas mais debatidos na área de ciência de dados. Somente escolher um conjunto de algoritmos e analisar qual possui a melhor performance para o problema, não entregará o melhor resultado. Sempre que falamos de treino e otimização de modelos de machine learning, falamos de Hiperparâmetros. Mas o que são eles e por que são tão importantes?
O que são hiperparâmetros e qual a sua importância?
Hiperparâmetros são atributos que controlam o treinamento do modelo de machine learning: com eles podemos tornar o modelo mais preparado para resolver um determinado problema da vida real. Fazendo a comparação com um carro, podemos associar os parâmetros com o motor e a gasolina e os hiperparâmetros são como a direção, o sensor de velocidade e retrovisores. O carro funciona somente com motor e gasolina. Contudo, sem os outros equipamentos, podemos levar o veículo a um desastre porque não teríamos o controle dele.
Por isso que os hiperparâmetros são tão importantes para um algoritmo! Eles previnem o modelo de aprender apenas com os dados mostrados (overfitting e underfitting), tornando-o capaz de generalizar para outras situações possíveis.
Muitas vezes, eles são deixados de lado, pois os frameworks deixam os seus valores em defaults nas suas funções. Uma situação bem clara é o RandomForest do sklearn:
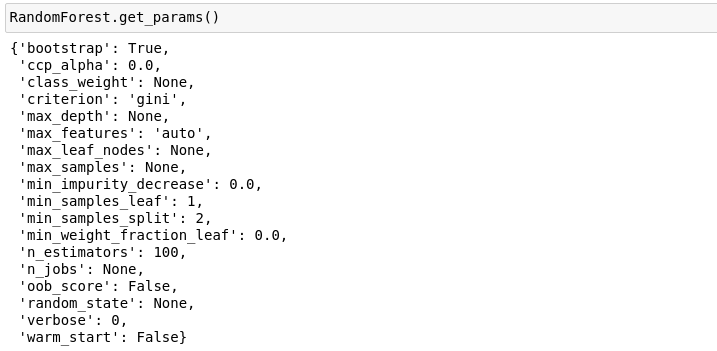
Percebam que todos os hiperparâmetros estão com valores pré-estabelecidos.
Sabendo que todos os modelos possuem hiperparâmetros, então, como encontrar o melhor? Esta resposta não é fácil, pois varia de algoritmo para algoritmo, do tipo de dados, das versões dos frameworks, da linguagem de programação e da plataforma (seja local ou cloud). Modelos de deep learning são ainda mais complexos nesse aspecto, já que são formados por camadas e cada uma delas possui células com hiperparâmetros:
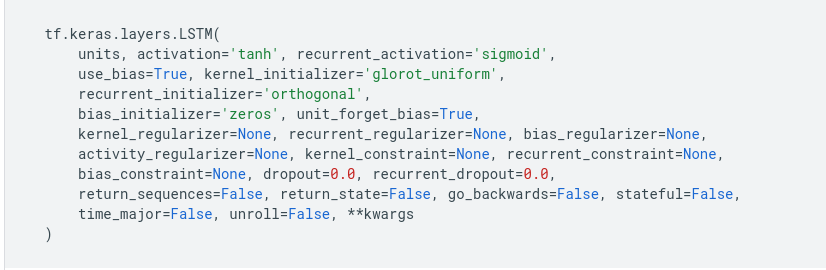
Retirado do site da documentação: https://www.tensorflow.org/api_docs/python/tf/keras/layers/LSTM
À medida que aumentamos esses hiperparâmetros, tanto o tempo treinamento e de teste aumentará. Segundo o livro, The Elements of Statistical Learning: Data Mining, Inference, and Prediction, se você regular o `max_depth` ou `n_tree` o modelo terá um desempenho melhor, porém, não adiantaria ter um algoritmo de alta performance enquanto a inferência demora mais tempo. Seria um fiasco colocá-lo em produção.
Como escolher os melhores Hiperparâmetros?
Para essa escolha, não é recomendado alterar os valores um de cada vez e ir computando os melhores resultados. Isso não seria eficiente em tempo e provavelmente não seria encontrado o melhor valor possível para o problema.
Por isso utilizamos técnicas como Grid Search ou Random Search aliados ao K-Fold, que são métodos específicos para trabalhar com o problema de forma programática - ou seja, o algoritmo encontrará a melhor solução.
O Grid Search testará todas as combinações a partir de um grid de hiperparâmetros pré-definido pela equipe para mais informações vejam este link). O Random Search, por sua vez, não testará todas as combinações, estando limitado a um valor de testes dos hiperparâmetros estipulado pela equipe antes de rodá-lo (para mais informações vejam este link). O objetivo é encontrar o melhor modelo ou um caminho de como equilibrar os hiperparâmetros.
Por fim, o K-Fold é uma forma de dividir os dados em K conjuntos para treinar e testar com estas diferentes partes. Se for escolhido K = 10, haverá 10 partições no conjunto de dados, sendo uma para treino e as outras nove para teste.
Após uma etapa de treino e teste, o algoritmo roda novamente, mas com uma nova partição de teste e treino. O objetivo do K-Fold é verificar a capacidade de generalização de um modelo dado um determinado conjunto de hiperparâmetros, assim, é mais provável vermos se há overfit ou não com ele.
Para avaliar a performance de um hiperparâmetro, não se deve levar em consideração somente os valores das métricas de classificação dos modelos. É necessário levar em conta o tipo de problema (classificação, ranqueamento, clusterização, etc.), o tempo de treino e teste e até mesmo regras específicas de negócio.
Como os hiperparâmetros funcionam na prática?
Para ilustrar melhor as duas técnicas, trouxemos dois exemplos: O primeiro utiliza Grid Search e K-Fold para avaliar o melhor conjunto de hiperparâmetros do modelo Random Forest do sklearn para o dataset íris.O segundo, por sua vez, utiliza Random Search e K-Fold, mas com um modelo diferente, um de deep learning.

O exemplo acima exibe os valores dos hiperparâmetros e também o resultado do modelo, que possui uma acurácia de 96%. Logo abaixo, num um modelo simplificado de deep learning, foram testados os hiperparâmetros de `batch_size` e `n_epochs` (é possível testar com muito mais opções - veja neste link quais outros hiperparâmetros poderiam colocar numa célula de mlp link).


Para conferir com mais detalhes esse código, acesse o nosso repositório no Github.
O que aprendemos sobre hiperparâmetros?
Quando falamos de algoritmos de machine learning ou deep learning, não podemos deixar de falar de hiperparâmetros. Como foi mostrado, eles são essenciais para direcionar um modelo, melhorando o seu desempenho e evitando que o mesmo aprenda somente os dados que foram treinados (portanto, generalizando para situações da vida real). Contudo, para a identificação do conjunto de hiperparâmetros mais adequado ao problema são necessárias técnicas que otimizem o seu uso testando as suas diversas combinações. Portanto, podemos ser categóricos quanto a isso: Nunca deixem de lado a otimização dos hiperparâmetros!