

Quando ouvimos sobre a potencialidade da aplicação da Inteligência Artificial (IA) para impulsionar a competitividade do negócio, a primeira coisa que pensamos é: Preciso fazer isso na minha empresa! Ainda mais em um mundo cada dia mais VUCA (Volátil, Incerto, Complexo e Ambíguo).
E esse pensamento está correto! Com a quantidade e variedade de informações disponíveis para análise, precisaremos muito dos algoritmos como aliados para trazer insights acionáveis, ou seja, relevantes à tomada de decisão.
Porém, o que precisamos ter em mente é que, para um projeto que tem como objetivo a aplicação da IA ter sucesso, é provável que o caminho percorrido seja extenso e com muitas fases para validação e melhoria contínua.
Para entendermos um pouquinho mais sobre esse processo de desenvolvimento, vou trazer como exemplo uma pirâmide de necessidades para a aplicação da IA. Essa pirâmide traz de forma visual que, para termos insights automatizados, antes precisamos do básico, como uma boa Infraestrutura.
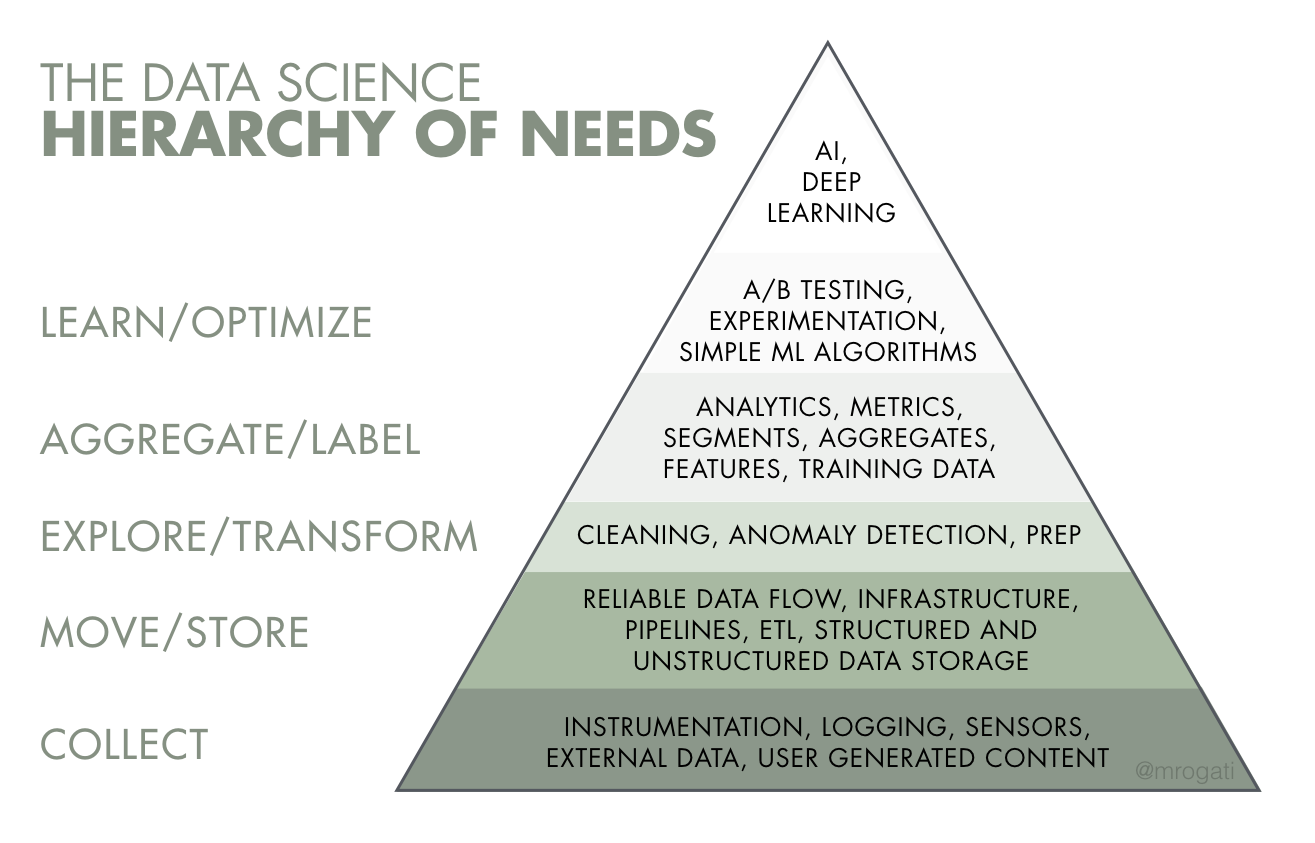
Na base da pirâmide temos a coleta de dados (collect). Muitas vezes não coletamos ou armazenamos dados que podem servir como agregadores na hora de aplicar algoritmos de machine learning. Por exemplo, se tivermos uma base de dados que, por mais que pareça volumosa pode não ter uma boa variedade de informações, é possível que o algoritmo não encontre um padrão nos dados que justifique o uso da IA. É como diz Cassie Kozyrkov, Cientista Chefe da Google, em seu artigo para towards data science:
O aprendizado de máquina é uma abordagem para automatizar decisões repetidas, que envolve encontrar padrões nos dados através do uso de algoritmos e, usá-los para fazer modelos que lidam corretamente com os novos dados. (Cassie Kozyrkov, tradução livre)
Então, a primeira coisa a fazer é uma análise exploratória dos dados e entender o que de fato podemos definir como padrão ou diferenciação nas informações, além de identificar como podemos enriquece-los com o uso de outras bases. Na DSB, todo projeto de Ciência de Dados inicia com um estudo ou uma análise exploratória, é exatamente nesse momento que identificamos a potencialidade das informações geradas pela empresa.
Em seguida temos armazenamento e transação dos dados (move/store). Para que um produto de dados com base em IA funcione, precisamos ter esses dados armazenados em uma estrutura que de suporte a coleta, o processamento, a transformação e o consumo da informação. Imagine que o algoritmo de machine learning irá receber novas informações ao longo do tempo, e que essas informações vão ter formatos e tempos variados, as definições de Infraestrutura e Governança serão o guia da empresa para realizar as modificações necessárias.
No centro da pirâmide temos exploração e transformação dos dados (explore/transform). É aqui que garantimos a qualidade dos dados consumidos pelos algoritmos e também, a qualidade dos insights gerados pela IA. Em um artigo para MIT Sloan, Langhe e Puntoni trazem isso através do ponto de vista dos executivos:
As empresas têm mais dados do que nunca, mas muitos executivos dizem que suas iniciativas de análise de dados não fornecem insights acionáveis e, no geral, produzem resultados decepcionantes. (Langhe e Puntoni, tradução livre)
Podemos fazer a seguinte analogia, se recebermos um diagnóstico de uma doença errado, não iremos tomar as ações necessárias para melhorar nossa saúde, o mesmo acontece com algoritmos que recebem dados erradas, eles passam resultados igualmente errados e que nos levam a tomar más decisões.
Durante uma fase de exploração dos dados é possível identificar os problemas relativos a qualidade dos dados consumidos para análise, mas principalmente permite definir quais as informações realmente relevantes aos objetivos do negócio.
Em penúltimo lugar, temos agregação e rótulos (aggregate/label). Essa é a fase com maior necessidade de experimentos e validações, é aqui que, entendendo os dados que possuímos, fazemos experimentos utilizando modelos algorítmicos variados e definimos qual desses modelos de machine learning é o ideal para atender aos objetivos propostos.
Gosto de comparar essa fase com o método científico. Conforme vamos fazendo as aplicações das técnicas de machile learning, vamos descobrindo mais sobre os dados e, consequentemente surgem novas hipóteses e testes que precisam ser realizados.
Nessa fase acontece a criação de segmentos através dos padrões encontrados nos dados, como por exemplo a segmentação de clientes féis ao negócio. Também é possível mapear pontos de atenção através da construção de métricas que auxiliam na identificação de gargalos no atendimento ao cliente, onde podemos descobrir que estes gargalos estão causando um abandono (churn) representativo ao negócio.
Por fim, e não menos importante, temos aprendizado e otimização (learn/optimize). Essa é a fase da pirâmide que exemplifica o porquê de um projeto de IA não terminar com um produto e estar em contínuo aprimoramento. Aqui são feitos experimentos e testes em cima dos resultados obtidos pelo algoritmo e, com essas informações, retroalimentamos o algoritmo, para que assim ele possa aprender com seus erros, fazendo uma analogia à nós, seres humanos.
Para dar continuidade a um projeto de IA a empresa precisa ter profissionais habilitados a trabalhar em todo o processo, desde a coleta até a disponibilização da informação para consumo. Lembrando que ter uma IA trazendo informações relevantes de forma automatizada não inclui uma transformação apenas da área técnica da empresa, mas inclui principalmente uma transformação cultural na tomada de decisão pelos executivos.
Muitas pessoas usam os dados apenas para se sentir melhor sobre as decisões que já tomaram. (Cassie Kozyrkov, tradução livre)
Aqui na DSB auxiliamos na formação de squads multidisciplinares, impulsionando a transformação cultural através de mentorias que acontecem ao longo do desenvolvimento dos projetos. Somos especializados na identificação do potencial dos dados disponíveis nas empresas, acelerando projetos que visam o uso da IA para criação de insights acionáveis.
Podemos perceber que usar técnicas de IA para alavancar as decisões e tornar a empresa mais competitividade é um processo denso, passando pela construção de uma base forte que prevê todas as fases abordadas neste artigo: coleta, armazenamento, transformação, agregação e aprendizado. Apenas depois de passarmos por elas é que poderemos dizer que aplicamos Inteligência Artificial.
Um ponto não abordado na pirâmide, mas tão relevante quanto, é como a empresa irá consumir esses insights. Desde a definição das áreas que terão acesso até o formato de acompanhamento, como por exemplo através de alertas ou dashboards à vista. O importante nesse ponto é entender qual o melhor formato para facilitar a ação dos gestores.
Se você está se sentindo um pouquinho atrasado, essa é uma boa sensação, agora aproveite ela e vá para ação. Mapeie os conhecimentos da sua equipe, se aprofunde nos detalhes sobre os dados da sua empresa, identifique quais os possíveis gargalos na criação de análises e quais delas estão sendo realmente utilizadas, fale com seus gestores e liste informações que eles sentem falta. Com essas e outras informações em mãos, comece.
Comece pequeno, mas comece hoje!
Fontes: The AI Hierarchy of Needs, Data-Driven? Think again (Hackerenoon); Leading With Decision-Driven Data Analytics (MIT Sloan); When not to use machine learning or AI (towards data science).