


Senta que lá vem a história…
Neo4j é um banco NoSQL (banco de dados não relacional), ele é Open Source, está há mais de 10 anos no mercado. E finalmente, é um Graph Databases (Banco de Dados de Grafos), um dos mais populares desse tipo senão o mais popular...
Segundo o próprio site do Neo4j, o banco de dados oferece suporte oficial para as seguintes linguagens de programação: .Net, Java, JavaScript, Go and Python. E sua comunidade suporta as seguintes: PHP, Ruby, R, Erlang, Clojure e C/C++.
Tanto o Neo4j como outros graph databases como Infinite Graph, InforGrid, HyperGraphDB, etc, abrangem uma ampla gama de possibilidades de armazenamento de informações e são considerados fundamentais para ecossistemas de BigData. Ao pensar em uma quantidade vasta de relacionamentos, o modelo relacional ficaria com o desempenho comprometido, pois precisaria de queries muito complexas com vários joins, o banco de grafos resolve isso de uma forma mais simples e direta.
O modelo orientado a grafos possui três componentes básicos:

- Os nodes - também chamados de nós, nodos ou vértices do grafo - são responsáveis por guardar os dados de uma entidade. É super indicado dar nomes (labels) para os nodos, pois com os Labels fica mais fácil fazer consultas, visualizar os dados além de tornar a modelagem de dados mais "bonita";
- Os relacionamentos - ou links ou edges ou ainda arestas - representam os relacionamentos (!) entres os nodes. Esses links possuem uma direção e isso é uma das características mais importantes dos relacionamentos, por exemplo um link Node 01 aponta para o Node 02, mas não necessariamente o inverso (Node02 -> Node 01);
- As propriedades, ou atributos, dos nós e relacionamentos.
Nada de tabelas, campos e índices, que maravilha não?!
Ah! Mas então eu vou deixar de usar um banco relacional e só utilizar grafos? Não! Como tudo na vida, saber qual tipo de banco usar na sua aplicação, precisa de análise, critérios e equilíbrio. Senão o que seria uma vantagem pode virar um enorme problema.
E antes de partir para um exemplo bem legal (para quem curte Game of Thrones principalmente), vamos falar um pouco sobre o Cypher.
Neo4j e Cypher
Cypher é a linguagem oficial de consultas do Neo4j, com ela podemos criar, modificar e procurar os dados em uma estrutura baseada em um conjunto de grafos e seus relacionamentos. Entenda Cypher como um substituto do SQL.
Aspectos Chaves do Cypher:
1 — É uma linguagem Declarativa, diga o que você quer e não como;
2 — Totalmente Expressiva, se você consegue descrever o que quer de forma simples, ou seja numa linguagem natural, dá pra fazer no Cypher;
3 — Conceitos simples e bem similares aos de linguagens de consultas já conhecidas usadas com bancos SQL. Se você está acostumado com SQL, vai enxergar vários paralelos mas já deixo avisado que apanhei um pouco para acostumar com a linguagem!
4 — E é óbvio, Orientada a Grafos, ou seja, foi feita para banco de dados grafos.
Cypher Query Language — Bora entender um pouco como funciona?
Abaixo você encontrará os principais comandos do Cypher. E é claro que para maiores informações, ver comandos mais avançados e a diversas funções que ele suporte, é sempre bom verificar a documentação oficial.
- MATCH: É o SELECT do mundo SQL. É com ele que fazemos consultas no Neo4j. O padrão principal de um MATCH é ()-[]-(). Ou seja, MATCH (um node)-[relacionado]->(com outro node), ou ainda, MATCH (um node {com filtro de atributo})-[relacionado]->(com outro node).
- RETURN: Podemos dizer que ele é responsável por trazer as informações que queremos. É tipo quando fazemos o SELECT * FROM xxxxx ou SELECT tabela.campo, tabela.campo1 FROM xxxxx. É o RETURN que indica o que queremos trazer do MATCH, se é o node ou o relacionamento ou ambos, por exemplo.
- CREATE: É com este comando que você cria nodes e relacionamentos.
- MERGE: É a união do CREATE com MATCH em um só comando. Você consegue criar nodes e relacionamentos, principalmente com um grande número de dados. E caso o item já existir não será criado novamente e sim feita uma fusão das informações.
- SET: Utilizado para alterar as propriedades (atributos) de um node ou relacionamento.
- REMOVE: Com este comando é possível remover as propriedades (atributos) de um node ou relacionamento.
- DELETE: Responsável por apagar os nodes e as relações.
- WITH: O resultado de um MATCH pode gerar uma nova informação, uma nova query, que vai ser usada um novo MATCH ou em um RETURN. É utilizado em queries mais complexas para ajudar a expor um resultado de forma simples e mais rápido.
- OPTIONAL MATCH: É o mesmo conceito do MATCH porém o retorno não é obrigatório, pode ter valores nulos. Pode ser comparado ao outer join do SQL.
- COLLECT: É uma função de agregação que retorna uma lista contendo os valores retornados por uma outra expressão.
Que tal um exemplo com GoT? Sim, Game of Thrones…
E porque não?! Game of Thrones é um exemplo perfeito para aprender Neo4j já que cada personagem pode se relacionar com outros de diversas formas e podem ter atributos diferentes.
SPOILER ALERT: A partir deste ponto, contém spoilers de toda a série

Vamos usar duas casas: Stark e Targaryen, e os personagens: Jon Snow, Ned Stark e Daenerys Targaryen. E os relacionamentos? Vixe! Vários e por esse motivo fazer essa estrutura não ficaria nada performática em um banco relacional.
Primeiro vamos criar as duas casas e os personagens e relacioná-los:
// Cria os personagens com o comando MERGE
MERGE (p1 : Personagem {nome: 'Jon Snow', titulo: 'Rei do Norte', animal_estimacao: 'Lobo - Ghost'})
MERGE (p2 : Personagem {nome: 'Ned Stark', titulo: 'Lorde de Winterfell', frase: 'The Winter is Coming'})
MERGE (p3 : Personagem {nome: 'Daenerys Targaryen', titulo: 'Khaleesi, A Não-Queimada, Mãe de Dragões...' })
// Cria as duas casas dos personagens, com seus atributos
MERGE (c1 : Casa {nome: 'Stark', simbolo: 'Lobo' })
MERGE (c2 : Casa {nome: 'Targaryen', simbolo: 'Dragao Vermelho de 3 cabeças' })
// Cria os relacionamentos entre personagens e suas casas
MERGE (p1)-[r1: PERTENCE_A_CASA]->(c1)
MERGE (p2)-[r2: PERTENCE_A_CASA]->(c1)
MERGE (p3)-[r3: PERTENCE_A_CASA]->(c2)
// Elementos retornados pela consulta
RETURN p1, p2, p3, c1, c2E o resultado:
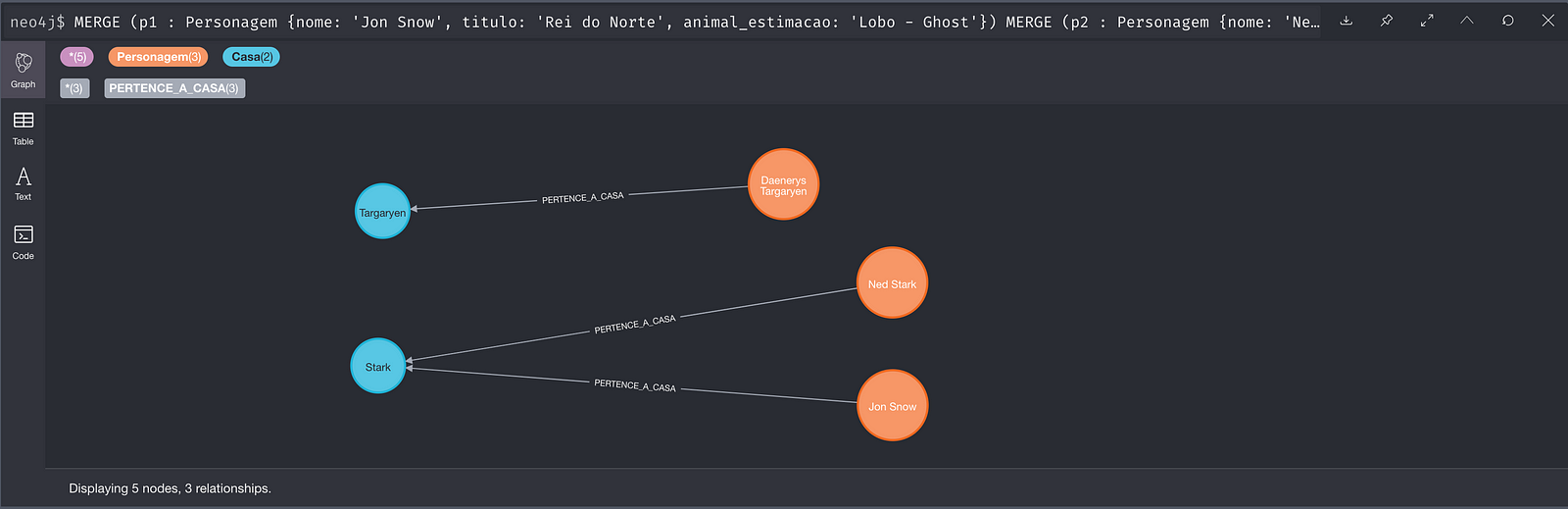
Agora podemos continuar criando mais relacionamentos com propriedades. Por exemplo, podemos incluir um atributo de "Temporada" ao relacionamento, já que Jon Snow no inicio da série era Filho Bastardo de Ned Stark, e quase no final descobrimos que na verdade ele era Sobrinho (eu avisei que tinha spoiler).
// Encontrar os registros já criados e dar um nome (como se fosse atribuir um valor a uma variável para usar depois) e fazer o MERGE para criar os relacionamentos
MATCH (p1 : Personagem {nome: 'Jon Snow'}), (p2 : Personagem {nome: 'Ned Stark'}), (p3 : Personagem {nome: 'Daenerys Targaryen'}), (c1 : Casa {nome: 'Targaryen'})
MERGE (p1)-[:FILHO_BASTARDO {Temporadas:'1 - 6'}]->(p2)
MERGE (p1)-[:SOBRINHO {Temporadas:'6 - 8'}]->(p2)
MERGE (p1)-[:SOBRINHO {Temporadas:'6 - 8'}]->(p3)
MERGE (p1)-[:SE_APAIXONOU]->(p3)
MERGE (p1)-[:DOBROU_O_JOELHO]->(p3)
MERGE (p3)-[:TIA {Temporadas:'6 - 8'}]->(p1)
MERGE (p2)-[:PAI {Temporadas:'1 - 6'}]->(p1)
MERGE (p2)-[:TIO {Temporadas:'6 - 8'}]->(p1)
MERGE (p1)-[:PERTENCE_A_CASA]->(c1)O que resultaria nessa estrutura:
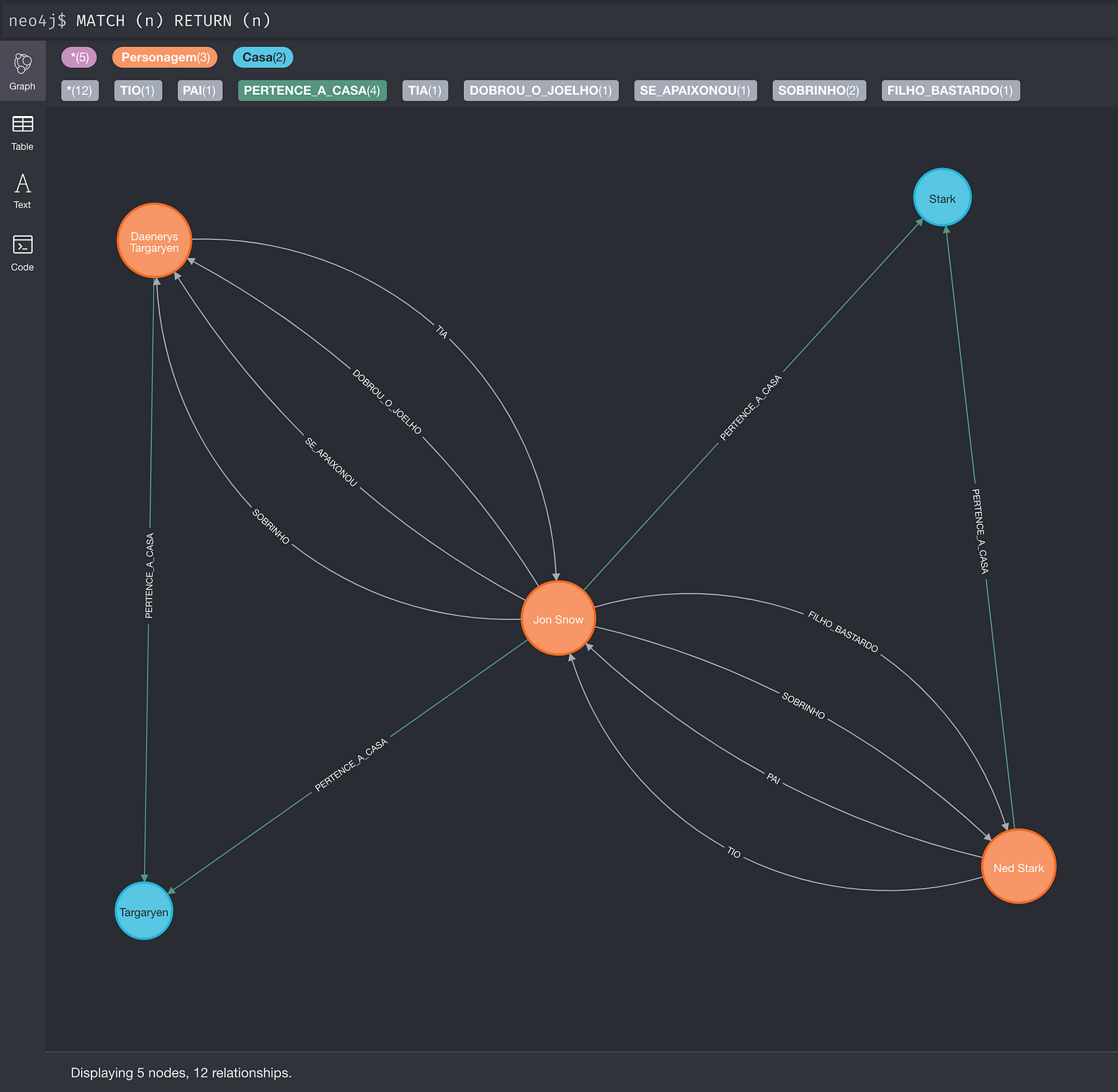
Para não alongar muito aqui no post, colocamos alguns exemplos de queries Cypher no GitHub. Lá você vai encontrar todos os scripts para simular esse exemplo de GoT com Neo4j, e muitos outros. Fique a vontade para conferir o repositório: blogpost_neo4j_got.
E olha só como ficou o schema final desse primeiro teste:
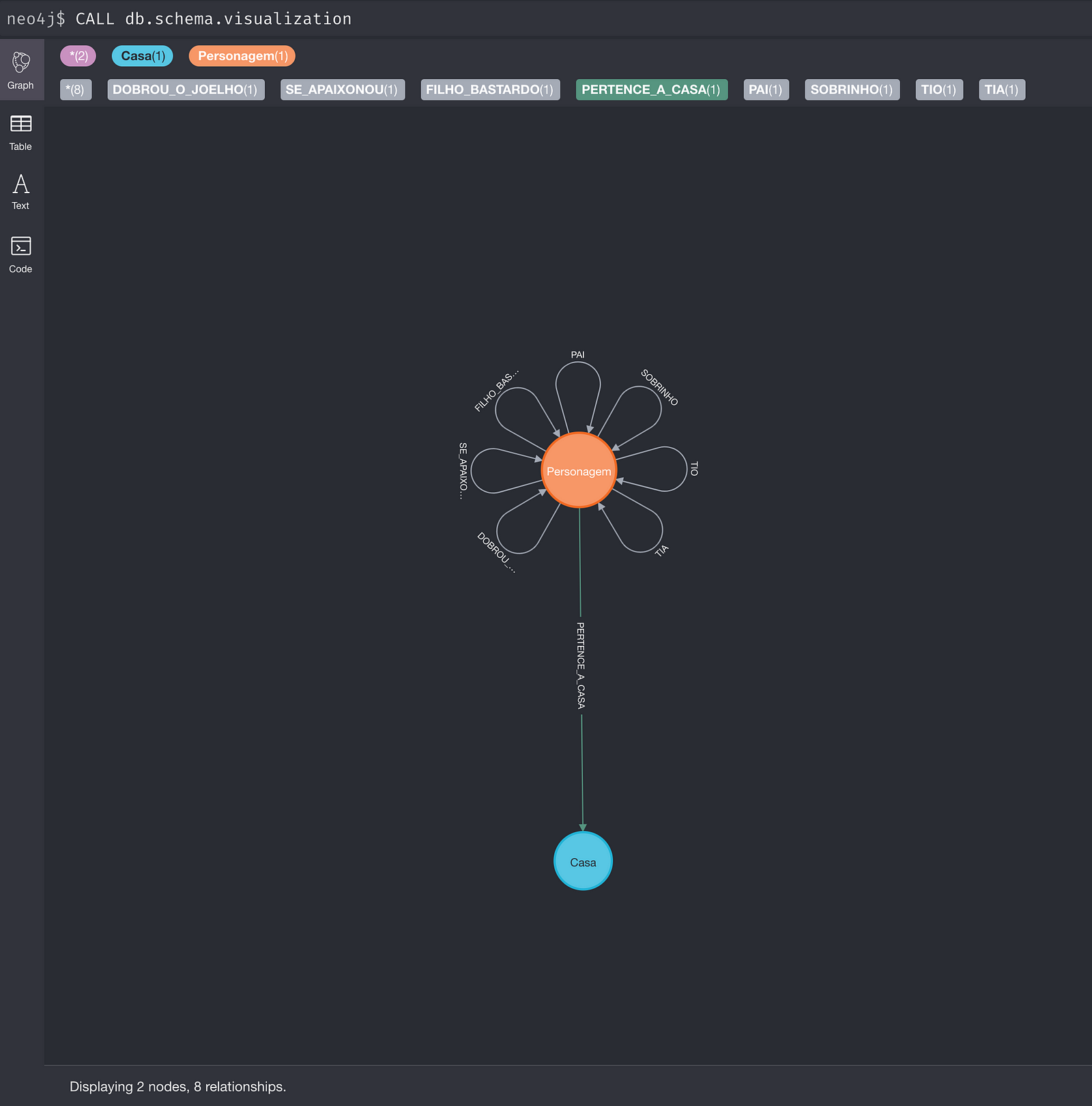
Que tal modelar as relações, batalhas, mortes e traições de Game of Thrones? Bom, isso fica para um próximo post. Em breve deve pintar por aí outro artigo e repositório cheio de informações sobre GoT, com várias dicas sobre Neo4j e Cypher, além de alguns insights baseados em análises dos dados.
E quem sabe no futuro brincar um pouco com a série alemã Dark do Netflix.
Banco de Grafos e AWS

Como eu sou apaixonada por Cloud, o que seria de mim sem um blog post que não falasse sobre algum serviço da AWS.
Segundo a AWS: "O Amazon Neptune é um serviço de banco de dados gráfico rápido, confiável e totalmente gerenciado que facilita a criação e a execução de aplicativos que trabalham com conjuntos de dados altamente conectados. O núcleo do Amazon Neptune é um mecanismo de banco de dados gráfico com projeto específico e alta performance, otimizado para armazenar bilhões de relacionamentos e consultar os gráficos com latência de milissegundos. O Amazon Neptune oferece suporte aos modelos de gráficos comuns Property Graph e RDF do W3C, bem como a suas respectivas linguagens de consulta TinkerPop Gremlin e SPARQL.".
Principais características:
- Totalmente gerenciado;
- Alta Disponibilidade e Resiliência;
- Réplicas de leitura. É Multi-AZ;
- Backups são feitos continuamente no S3 (são automáticos, incrementais e contínuos, e não afetam a performance do banco de dados);
- Seguro. Principalmente, se utilizar dos artifícios que a AWS oferece como VPC, KMS (Criptografia), e recursos do IAM — sempre bem configurados e abusando das melhores práticas.
Em breve devo fazer uma POC com o Amazon Neptune e compartilho minha opinião a respeito e monto um Hands-On bem legal. E é claro, fazendo uma breve comparação com o Neo4j. Que tal?!