

O AWS S3 ou Amazon Simple Storage Service, é um dos serviços mais conhecidos e antigos da AWS e é claro que vocês já devem estar cansados de saber disso. Este artigo tem a intenção de dar uma introdução um pouco diferente sobre o S3, além de falar um pouco sobre as classes de armazenamento que existem, suas diferenças e onde podem ser aplicados. Afinal, é possível encontrar vários tutoriais ensinando como criar buckets e setar permissões, e muitos deles inclusive tratam de alguma frente especifica.
E que tal começarmos com "O que o S3 não é?"
Ou melhor para que ele não serve? Ele não é indicado para nada que dependa de armazenamento em bloco, por exemplo, não é possível instalar e rodar um sistema operacional e/ou banco de dados nele. Quem faz esse papel é o Amazon Elastic Block Store (EBS). Ou ainda, ele não é indicado para aplicações que depende de muito IOPS* e/ou Throughput**, o correto seria utilizar o Amazon Elastic Block Store (EBS) e/ou Amazon Elastic File System (EFS).
*IOPS (Input Output Operations Per Second ou Operações de Entrada e Saída por Segundo) - é o tempo em segundos que se leva para completar um operação de entrada e saída de dados - read/write.
**Throughput - pode ser traduzido como a taxa de transferência efetiva de um sistema - é a quantidade em Kbps, Mbps ou Gbps de dados transferidos de um lugar a outro, ou a quantidade de dados processados em um determinado espaço de tempo.
Agora que já sabemos o que ele não é, que tal entendermos o que significa ser um Object-Storage ou serviço de armazenamento de objetos?
É basicamente um local onde podemos armazenar objetos, ou seja, arquivos - imagens, arquivo de texto, vídeos, documentos, entre outros.
O tamanho de cada arquivo pode variar entre 0 bytes até 5TB. É possível ter um número ilimitados de objetos (arquivos) dentro de um único bucket S3 e o AWS S3 pode armazenar praticamente uma quantidade ilimitada de dados. Não há taxa mínima, você paga pelo que usar.
E o que são buckets S3?
Nada mais que pastas onde armazenamos nossos arquivos. O nome do bucket S3 é universal - devem ser únicos globalmente - na verdade eles devem ser exclusivos de uma partição***.
***"Uma partição é um agrupamento de regiões. A AWS atualmente tem três partições: aws (regiões Standard), aws-cn (regiões da China) e aws-us-gov (regiões GovCloud [EUA] da AWS)."
Sempre devemos escolher uma região no momento da criação dos buckets que irá armazenar os dados, pois o console do AWS S3 é global, permite a visualização de N buckets que temos em N regiões, mas os buckets são criados em regiões específicas.
Os nomes dos buckets podem conter de 3 até 63 caracteres - sempre letras minúsculas e podem ter números, hífens(-), pontos(.). Por padrão, podemos criar até 100 buckets por conta, são os famosos Soft Limits da AWS ou AWS service quotas, mas se necessário, esse limite pode ser aumentado até 1.000.
Consistência de dados do Amazon S3
- Dados consistentes para leitura após a escrita (PUTS) - Assim que incluir um arquivo no bucket ele estará imediatamente disponível.
- Dados eventualmente consistentes após alteração ou deleção de arquivos ou delete (PUTS ou DELETES) - Pode-se levar um tempo para replicação do dado, e enquanto isso você poderá consumir dados antigos.
Quais são as Storage Classes ou Classes de Armazenamento?
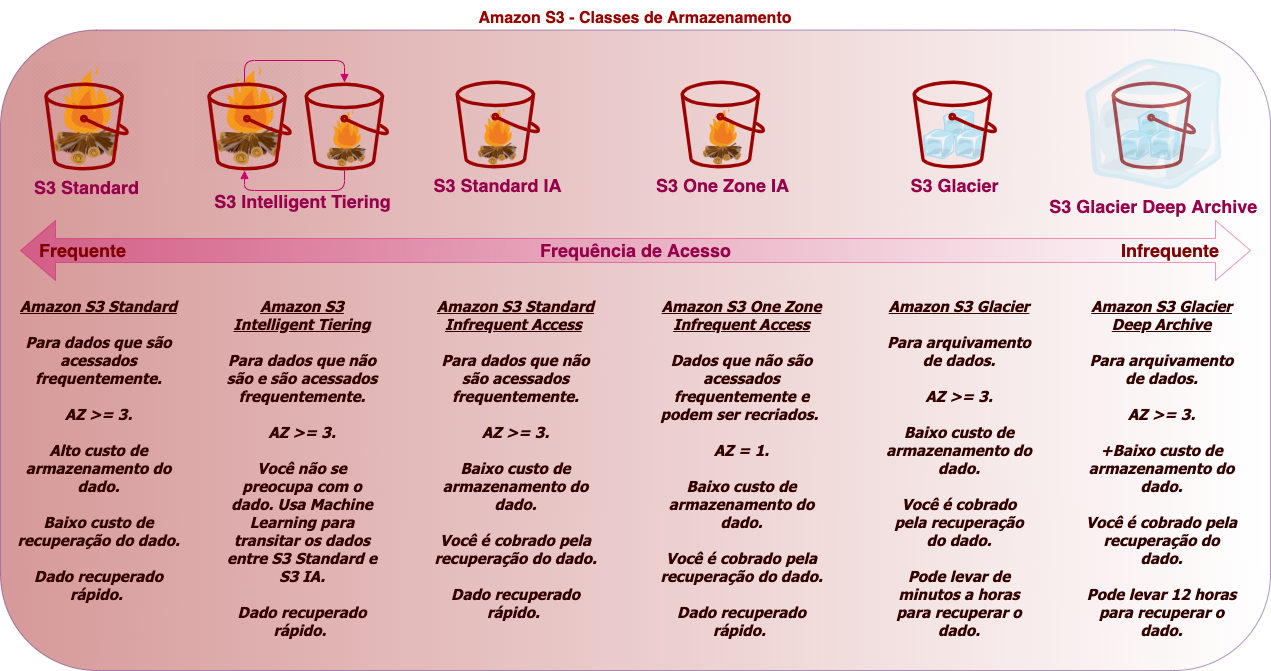
Apesar de não ser o foco, mas antes de falar sobre as classes, acho interessante saber o que compõe o custo do S3, onde você pode pagar: pelo Armazenamento (por GB), por Requisições (Requests - PUT,LIST, GET, etc) e Recuperação de dados, por Transferencia de Dados e pelo Gerenciamento e Replicação.
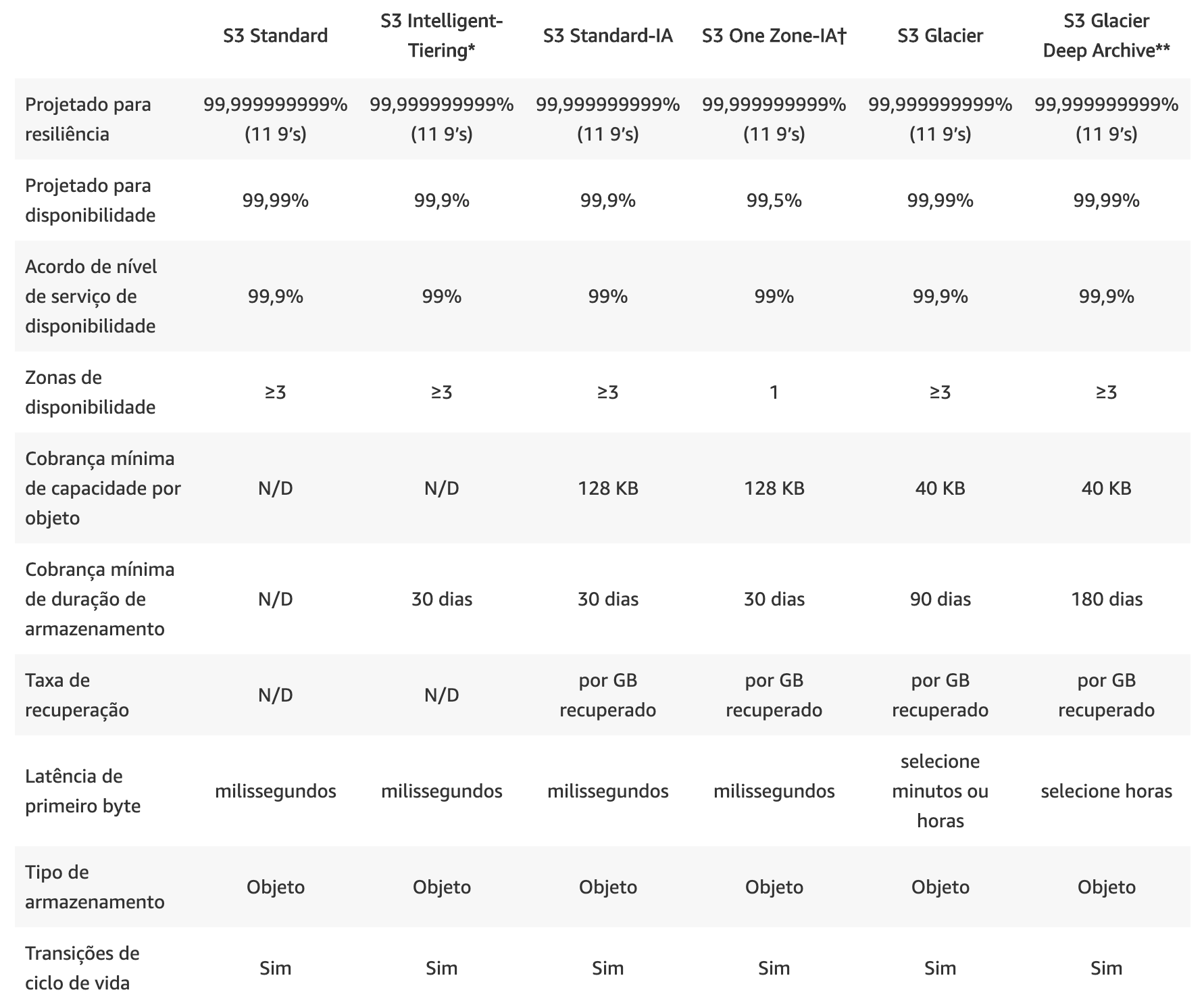
- Amazon S3 Standard (S3 Standard) - É o mais conhecido. Pode ser definido como de Uso Geral, ou seja, é para qualquer tipo de dado que é acessado frequentemente. Durável, acessível de imediato, "mais caro" dentre os 6. Armazena dados no mínimo em três Zonas de Disponibilidade (AZs). É adequado para uma grande variedade de casos de uso (aplicativos na nuvem, sites dinâmicos, distribuição de conteúdo, aplicativos móveis e de jogos e dados analíticos de Big Data, etc).
- Amazon S3 Standard-Infrequent Access (S3 Standard-IA) - Pode ser definido como de Acesso Infrequente. O armazenamento é mais barato porém paga-se pelo resgate do dado. Armazena dados no mínimo em três Zonas de Disponibilidade (AZs). É adequado para arquivos que são armazenados por um período longo de tempo sem acesso, como backups e dados que são usados em caso de um desastre (disaster recovery). O que se deve ter em mente quando se pensa em S3 IA é: Dados que exigem acesso relativamente raro, mas, se necessário, devem ser acessados rapidamente. É mais barato que o S3 Standard.
- Amazon S3 Intelligent-Tiering (S3 Intelligent-Tiering) - É o inteligente da turma. Pode ser definido como de Acesso Desconhecido, Imprevisíveis ou Dinâmico. Armazena dados no mínimo em três Zonas de Disponibilidade (AZs). Ele é um misto do S3 com o S3 - IA, e por uma pequena taxa mensal (automação e monitoramento por objeto) a AWS usa machine learning para identificar quais objetos não foram utilizados num período e move esses dados para uma camada de acesso infrequente e com isso o custo do dado armazenado cai, já os dados que são acessados com frequência ficam na camada Standard, ou seja, o dado fica transitando entre as camadas dependendo do tanto que é acessado e você não precisa fazer nada para tal. O custo acaba sendo menor.
- Amazon S3 One Zone-Infrequent Access (S3 One Zone-IA) - Pode ser definido como de Acesso Infrequente. Possui as mesmas características do Amazon S3 Standard-Infrequent Access (S3 Standard-IA), só que armazena os dados em apenas uma AZ (Zona de Disponibilidade) e por esse motivo é mais barato que o S3 IA. É adequado para dados acessados com pouca frequência, mas que não precisam da disponibilidade e da resiliência S3 Standard ou S3 IA. É uma excelente opção para armazenar cópias de backup secundária de dados locais ou de dados que possam ser recriados com facilidade.
- Amazon S3 Glacier (S3 Glacier) - É mais barato que todos os anteriores. É para Arquivamento de dados. Armazena dados no mínimo em três Zonas de Disponibilidade (AZs). Nos dá três opções de recuperação, que podem levar de alguns minutos a várias horas para disponibilizar os dados (Expedited - 1 a 5 minutos, Standard - 3 a 5 horas, Bulk - 5 a 12 horas). Exemplos de uso: Arquivos de recursos de mídia (boletins de notícias), Arquivos de organizações que trabalham na área da saúde (informações dos pacientes), Dados obtidos durante pesquisas científicas, Cópias de backup de bancos de dados com armazenamento longo, Substituição de mídia analógica, etc.
- Amazon S3 Glacier Deep Archive (S3 Glacier Deep Archive) - É o mais barato de todos. É para Arquivamento de dados. Armazena dados no mínimo em três Zonas de Disponibilidade (AZs). Pode levar até 12 horas para recuperar os dados. Foi projetado para clientes que mantêm conjuntos de dados por mais de 7 ou 10 anos para cumprir requisitos de conformidade normativa, especialmente em setores altamente regulados como serviços financeiros, saúde e setores públicos.
Portanto, o Amazon S3 é muito mais do que um simples serviço de armazenamento de dados, que tem como principais vantagens: escalabilidade, disponibilidade de dados, segurança e performance. Além de tornar possível "armazenar e recuperar qualquer volume de dados, a qualquer momento, de qualquer lugar na web".
Possui uma interface web muito simples e intuitiva no console da AWS. Pode e deve ser usado para diversas frentes (sites, análises de big data, data lakes, backup e restore, entre outros), inclusive nós construímos um pipeline de dados utilizando o S3 e você pode ver um pouco sobre as ferramentas utilizadas neste artigo.
Ah! E não esqueça de proteger muito bem os seus buckets!!!

O serviço AWS S3 pode ser considerado peça chave em diversas arquiteturas e não devemos esquecer de dar aquela atenção especial às políticas de acesso e segurança de cada bucket S3. Só assim seu bucket estará protegido, evitando que informações sejam expostas desnecessariamente.
Espero em breve escrever um outro artigo para falar sobre outros itens interessantes no Amazon S3 como buckets policies, ACL's, across account, cross-region replication, entre outros. Que tal?!