

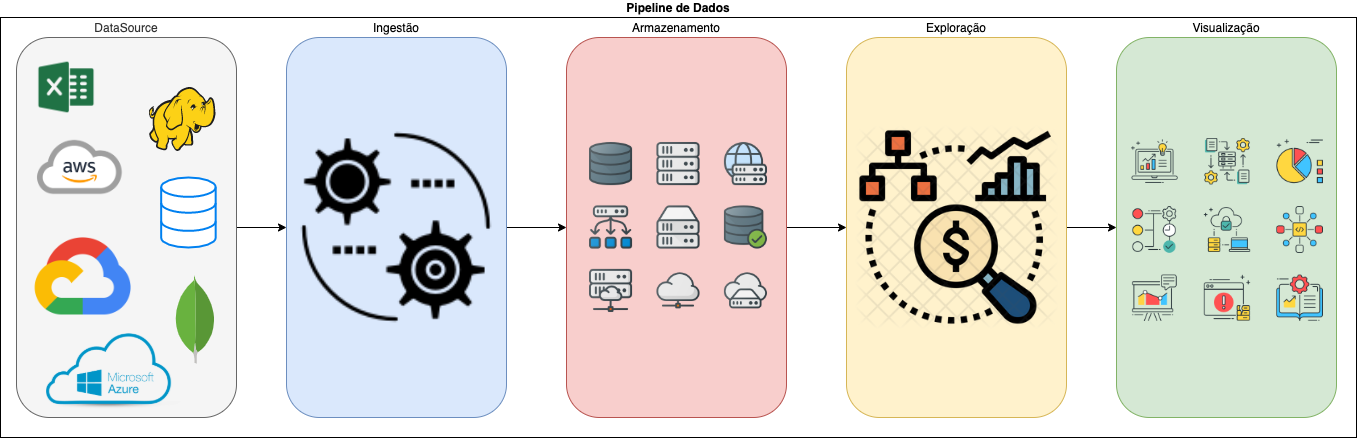
A AWS contém vários serviços que desempenham papéis parecidos e escolher o serviço mais apropriado para a sua pipeline de dados pode ser um desafio e tanto.
Nesse post, compartilho um pouco sobre as decisões de uma pipeline de engenharia de dados que construímos recentemente na AWS. Aqui você não encontrará detalhes de como configurar os serviços citados, nem das permissões que são necessárias mas garanto que vale a leitura. Vamos falar um pouco sobre cada um dos serviços AWS escolhidos, mostrando onde cada um se encaixaria em nossa pipeline de dados, além de fazer um breve comparativo com serviços de outras clouds.
A pipeline teria que atender a vários requisitos:
- a principal fonte de dados é um banco relacional;
- não travasse o consumo de dados já existente;
- que fosse flexível (hoje uso o serviço A, mas amanhã quero usar o B);
- que se adaptasse rapidamente às mudanças que poderiam aparecer;
- além do volume de dados, a ingestão teria que contemplar o armazenamento de diferentes tipos de arquivos;
- já o refinamento dos dados poderia ocorrer durante a ingestão ou após - gerando um nível ainda maior de refinamento;
- e a visualização não deveria ficar restrita a nenhuma tecnologia!
Pode-se dizer que de longe, o serviço mais importante utilizado, é o AWS IAM e que muitas vezes não recebe a devida atenção e mérito. Nele que as permissões e restrições de acesso serão definidas, uma frase que li esses tempos e faz todo o sentido é: "Por padrão tudo não é permitido, é sua responsabilidade liberar as permissões". Portanto, reserve um bom tempo no seu projeto para a criação e gerenciamento das permissões como um todo, desde a conta root como as contas de usuários, e dos serviços. E para começar nosso breve comparativo com outras clouds, tanto a Microsoft Azure (Azure identity and access management solutions) como a Google Cloud Platform (Cloud IAM) possuem esses serviços.
O ator principal dessa arquitetura é o serviço de armazenamentos de dados, o AWS S3 ou Amazon Simple Storage Service, ele é totalmente gerenciado pela AWS, escalável, resiliente e de baixo custo. Existem 6 tipos de categorias e as principais diferenças entre elas, seriam custo versus tempo de acesso ao dado. Em nosso teste iremos utilizar o mais conhecido, o S3 Standard, que pode ser explicado como sendo o armazenamento geral dos dados que são acessados frequentemente. Para isso, alguns buckets S3 foram criados com as devidas permissões. Tanto a Azure (Azure Blob Storage) como a Google (Cloud Storage) possuem esses serviços e, apesar de um detalhe ou outro ser diferente, o conceito é o mesmo.
Para facilitar e ainda aproveitar a oportunidade de conhecer um outro serviço totalmente gerenciado da AWS, utilizamos o AWS RDS (Amazon Relational Database Service) como datasource dos dados. Criamos uma instância MySQL, fizemos uma carga de tabelas e dados para iniciar nossos testes.
E foi nessa hora, que como uma boa DBA sentei e chorei, porque a facilidade em criar uma instância, configurar e gerenciar todos os recursos me deixou impressionada.

Pensando em nossa comparação com outras nuvens a AWS sai na frente, quando pensamos em players de mercado já que o RDS atende as seguintes frentes: Amazon Aurora, MySQL, MariaDB, Oracle, Microsoft SQL Server e PostgreSQL, já a Google possui o Cloud SQL (MySQL, PostgreSQL e SQL Server), e na Azure temos o Azure Database for (MariaDB, SQL, PostgreSQL ou MySQL).
Como ferramenta de ingestão de dados, testamos duas frentes uma com AWS DMS (Amazon Database Migration Service) e outra com o AWS GLUE. O AWS DMS realiza a migração de seu banco de dados (seja on premise ou na nuvem, de forma segura, rápida e sem atrapalhar seu ambiente produtivo) para a AWS e uma outra vantagem é que não precisa ser na mesma engine. Inclusive, a migração dos dados pode ser feita para um bucket S3, como foi realizado em nosso teste, ele salva arquivos CSV (Também é possível utilizar Parquet), e foi feito o teste com o load completo como alterações. Não foi encontrado nenhum serviço desse tipo na Google, e na Azure temos o Azure Database Migration Service.
Sobre o GLUE, é um serviço de ETL gerenciado da AWS, onde é possível criar um catálogo de dados (Glue Data Catalog), gerar e editar transformações, além do gerenciamento de jobs. Ele dá diversas opções para salvar os arquivos (CSV, JSON, Parquet, etc), e é possível utilizar Spark ou Scala para construir um job de ETL. Ainda não tenho uma opinião 100% formada, desde o início vivo um relação de amor e ódio com ele, mas uma coisa é certa, o AWS GLUE é uma ferramenta extremamente poderosa. Fizemos testes de ETL utilizando o RDS e Buckets S3 como Source e Buckets S3 como Target . Na Google, os serviços correspondentes seriam o Cloud Data Fusion + Cloud Data Catalog. Já na Azure, seriam Azure Data Factory + Azure Data Catalog.
Pensando na exploração dos dados armazenados nos buckets S3 em seus diversos formatos (CSV pelo DMS, Parquet e JSON pelo GLUE), utilizamos dois serviços o Amazon Athena e o Amazon Redshift. Vamos começar pelo Amazon Athena, é serveless, utiliza o Presto por debaixo dos panos e é utilizado como "conector" para realizar consultas SQL em dados que estão no S3 utilizando junto os catálogos do GLUE. Já o Amazon Redshift, é o famoso DW moderno, é o Data Warehouse na nuvem, com ele é possível fazer consultas diretamente no S3 com SQL e é extremamente fácil de gerenciar.
Para essa última comparação, temos algumas situações, falando do Athena primeiramente, não encontrei nenhum serviço semelhante nas outras nuvens, porém a própria Microsoft compara o Amazon Athena com o Data Lake Analytics, e um artigo no medium compara o Athena ao Big Query da Google, mas em ambos os casos acho que as ferramentas tem muito mais a oferecer que o Athena e a comparação não é muito justa. Já sobre o Amazon Redshift, temos o Azure Synapse Analytics na Azure e o Big Query na Google (Como eu conheço um pouco mais o Big Query, posso dizer que é uma excelente ferramenta também e possui uma interface mais amigável que o Redshift).
Para finalizar o pipeline, uma visualização bem simples foi realizada com o Power BI e com o Tableau, como não tenho muita experiência com essas ferramentas não quero estender muito, mas na minha humilde opinião, como usuária iniciante, o Tableau saiu na frente, tanto a configuração (para conectar e utilizar o Athena e o Redshift) quanto a usabilidade, ele é muito mais simples que o Power BI, além da interface ser muito mais amigável.
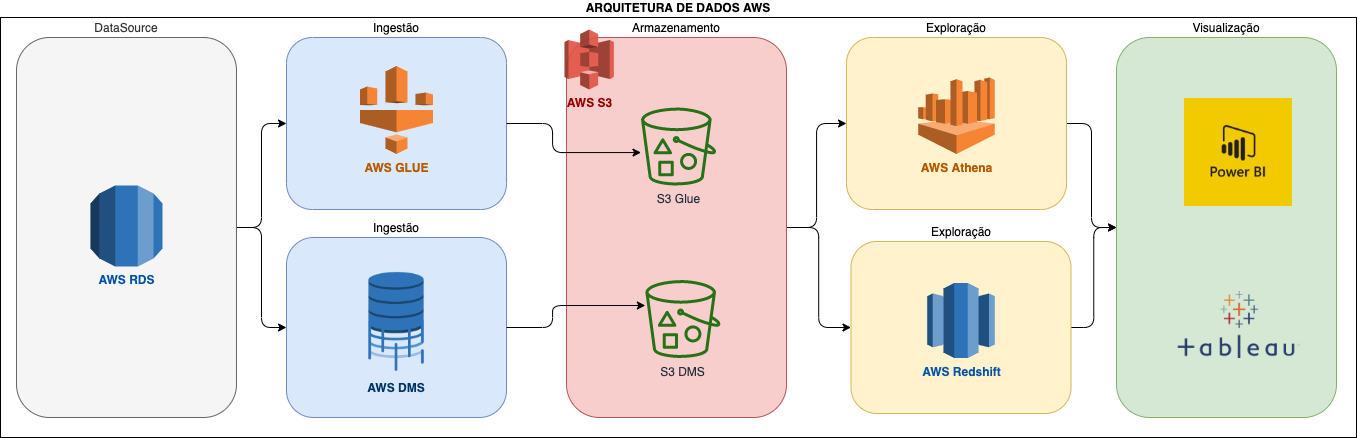
O desenho final da arquitetura você pode conferir acima e espero em breve possamos nos encontrar em um outro post para falarmos dos detalhes de cada serviço abortado aqui.